

Data-driven decision-making has become the foundation of business operations across every type of company, no matter the size or industry. Large volumes of data flow from many source systems to data warehousing, data lake, or analytics solutions.
What companies need to maximize their ROI from data is a fast, dependable, scalable, and user-friendly space that brings all kinds of data practitioners together — from data engineers and analysts to ML teams.
This is where Databricks comes in.
Databricks is a cloud-based data engineering tool that helps teams analyze, transform, and explore vast amounts of data. It’s a core platform for AI and machine learning teams and enables businesses to realize the full potential of their data — whether through real-time analytics, large-scale ETL pipelines, or cutting-edge AI models.
This blog will guide you through what Databricks is, how it works, key use cases, and why it’s transforming the way modern businesses manage data.
What is Databricks?
Databricks is a cloud-based data engineering and analytics platform designed to help teams work with massive amounts of data more effectively. Built by the creators of Apache Spark, it provides a collaborative environment to explore, process, analyze, and model data — all in one place.
The platform integrates smoothly with the major cloud providers: Microsoft Azure, AWS, and Google Cloud, allowing teams to tap into elastic compute and storage resources while managing security and governance with ease.
Whether you’re running ETL jobs, building dashboards, or training AI models, Databricks streamlines the process from start to finish.
What Problem Does Databricks Solve?

Most companies today use a combination of data lakes and data warehouses to store their information. But transferring data between them — especially at scale — can be a headache. The workflows are complex, often redundant, and don’t always play well together.
Databricks simplifies this landscape by introducing the lakehouse architecture, which merges the low-cost storage flexibility of a data lake with the structured performance and reliability of a data warehouse.
Instead of copying data between systems, you get one central source — making data easier to manage, query, analyze, and secure.
What is Databricks Used For?
Databricks is designed to handle every aspect of the data journey — from ingestion and transformation to analytics, visualization, and machine learning.
Here are some common ways businesses use Databricks today:
- Collecting all enterprise data in one place
- Handling both batch and real-time data streams
- Transforming and preparing data for analysis
- Performing large-scale computations
- Running queries and generating dashboards
- Building and deploying machine learning models
And because Databricks supports open-source languages like SQL, Python, Scala, and R, teams can use the tools they already know to solve data problems collaboratively.
Who Uses Databricks?
From tech giants to global banks, companies across industries rely on Databricks to make smarter decisions with their data.
Brands like Shell, Microsoft, Apple, Atlassian, HSBC, and Disney use Databricks to power their data infrastructure. But it’s not just for large enterprises — Databricks scales flexibly, making it accessible for mid-size companies and startups as well.
And because the platform supports multiple user roles, everyone from data engineers and analysts to ML engineers and BI teams can work in one shared environment.
Databricks vs. Databases, Data Warehouses, and Data Lakes
Before we move forward in exploring Databricks, it’s important to clarify the differences between databases, data warehouses, lakes, and Databricks, which proposes a brand-new architecture: data lakehouse.
Databases
A database is designed for everyday operations, typically used in Online Transaction Processing (OLTP). It stores structured data and supports tasks like reading, writing, and updating records — think of systems like banking transactions or customer orders. Databases are efficient for handling real-time transactions but aren’t optimized for large-scale analytics or complex queries across massive datasets.
Data warehouses
A data warehouse is built for analytics. It stores highly structured, cleaned, and integrated data from various sources — often both current and historical. Organizations use data warehouses to run business intelligence (BI) reports and dashboards. However, warehouses are generally expensive to scale and not suited for storing raw or semi-structured data like logs, images, or text.
Data lakes
A data lake stores large volumes of raw data in its original format — whether structured, semi-structured, or unstructured. It’s ideal for collecting data from diverse sources (e.g., IoT, applications, social media) and is often used as a low-cost storage solution. But data lakes lack built-in governance and performance tools, making them harder to query or manage directly for analytics and machine learning.
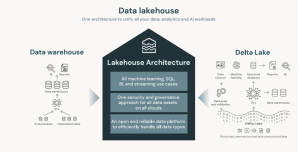
Databricks Lakehouse
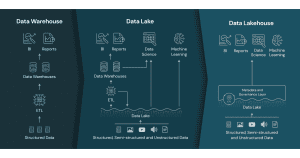
The data lakehouse is a new architecture that combines the scalability and low cost of data lakes with the structure and data management capabilities of warehouses — all within a single platform.
Databricks pioneered this approach, allowing teams to work on one unified source of data for BI, analytics, and AI/ML without needing to duplicate or transfer data between systems. It supports ACID transactions, schema enforcement, and strong governance — while also enabling real-time data processing and machine learning directly on the lakehouse.
By using the Databricks Lakehouse Platform, teams gain:
- A single place to store, process, and analyze all data
- Support for all data types and use cases
- Lower infrastructure complexity and cost
- Faster collaboration across data and AI teams
Key Features of the Lakehouse Architecture
The lakehouse model makes modern data work possible by supporting:
- ACID transactions to ensure consistency during concurrent data updates
- Schema enforcement and evolution to keep data clean and organized
- Built-in governance tools, including data lineage and access control
- Native BI support, so teams can run dashboards directly on raw data
- Storage and compute separation for scalable and cost-effective performance
- Support for structured, semi-structured, and unstructured data, including images, video, and text
- Streaming-first architecture for real-time analytics and monitoring
- Open-source compatibility with Apache Spark, Delta Lake, MLflow, and more
This makes Databricks not only powerful but also flexible enough to adapt as your business grows.
What Can You Build on Databricks?
Databricks is more than just a platform — it’s a foundation for modern data and AI innovation. Here’s what teams can do:
Data Engineering
Build and schedule data pipelines using SQL, Python, or Spark. Automate ETL workflows with tools like Delta Live Tables, and handle real-time streaming data with Auto Loader.
Databricks SQL
Databricks SQL (DB SQL) is a serverless data warehouse built on the Databricks lakehouse platform that lets users run all of their SQL and BI applications at scale with optimal performance, consistent data governance architecture, open formats and APIs, and preferred tools with no lock-in. With serverless, there’s no need to maintain, install, or grow a cloud infrastructure.
Machine Learning & AI
Use built-in ML capabilities to experiment, train, and track models. Integrate with MLflow for reproducible results, and even fine-tune large language models (LLMs) using your own data.
Real-Time Analytics
Databricks leverages Apache Spark Structured Streaming to work with streaming data and incremental data changes. Structured Streaming integrates tightly with Delta Lake, and these technologies provide the foundations for both Lakeflow Declarative Pipelines and Auto Loader.
Databricks Architecture Overview
Databricks operates on two main layers:
- Control Plane: Manages the backend services (like notebooks and jobs), hosted by Databricks.
- Data Plane: Where your data actually lives and gets processed — always in your own cloud account for full control and security.
This separation ensures that your data stays safe, while still benefiting from the scalability and collaboration of the platform.
Learn more about Databricks architecture.
Get Started with Databricks — with CMC Global
At CMC Global, we’re proud to be an official Databricks Consulting & SI partner, helping businesses modernize their data infrastructure and unlock real value from their data.
By combining our deep experience in data engineering, cloud, and AI development with the advanced capabilities of the Databricks Data Intelligence Platform, we empower organizations to move faster, make smarter decisions, and innovate with confidence.
Our team provides consulting, implementation, and ongoing support to help you:
- Design and build a modern data lakehouse architecture
- Set up robust ETL pipelines and automate data workflows
- Enable real-time reporting and AI-powered insights
- Ensure data security, governance, and compliance
- Customize ML solutions and generative AI models for your business
Whether you’re migrating from legacy systems or starting fresh, we’ll help you turn your data into a strategic advantage.
Conclusion
Data is your company’s most valuable resource — but only if you can unlock its potential. With Databricks, you get a single, powerful platform to manage your entire data lifecycle, from storage to insight to innovation.
And with CMC Global as your partner, you’ll move faster, scale smarter, and make better decisions, every step of the way.
📩 Contact us today to learn how we can help you power your business with Databricks.



