

In today’s fast-paced, data-driven world, businesses need flexible, scalable, and cost-effective systems to manage and analyze vast amounts of data. Traditional Enterprise Data Warehouses (EDWs) have long been the standard solution for structured data analytics and business intelligence. However, the rise of big data, AI, and machine learning has led to the emergence of a more modern architecture — the Data Lakehouse.
This blog dives into the key differences between Data Lakehouses and Traditional Data Warehouses, highlighting their architecture, benefits, and go-to-market alignment. We’ll explore why the Data Lakehouse architecture is quickly becoming the preferred choice for businesses seeking more agility and cost-efficiency in managing data.
What is a Traditional Enterprise Data Warehouse (EDW)?
A Traditional Enterprise Data Warehouse (EDW) is a system designed to store and process structured data from various sources like transactional databases, customer relationship management (CRM) systems, and enterprise resource planning (ERP) tools. These systems are primarily used for business intelligence (BI), data reporting, and historical analysis. EDWs follow a schema-on-write approach, where data is transformed and structured before being loaded into the system for optimized querying.
Key Features of Traditional EDW:
- Structured Data Only: Stores well-defined, clean, and transformed data.
- ETL Process: Data is extracted, transformed, and loaded into the warehouse.
- High Performance: Optimized for executing SQL-based queries and aggregations.
- ACID Compliance: Guarantees data consistency and reliability for mission-critical applications.
- Strong Governance: Provides excellent data governance and security, ensuring compliance with regulations such as GDPR and HIPAA.
Ideal Use Cases for EDW:
- Financial Reporting: Essential for tracking transactional data and meeting regulatory requirements.
- Business Intelligence (BI): Real-time and historical reporting for decision-making
- Customer Analytics: Segmentation, behavior analysis, and churn prediction.
- Supply Chain Management: Analyzing inventory levels and optimizing logistics.
What is a Data Lakehouse?
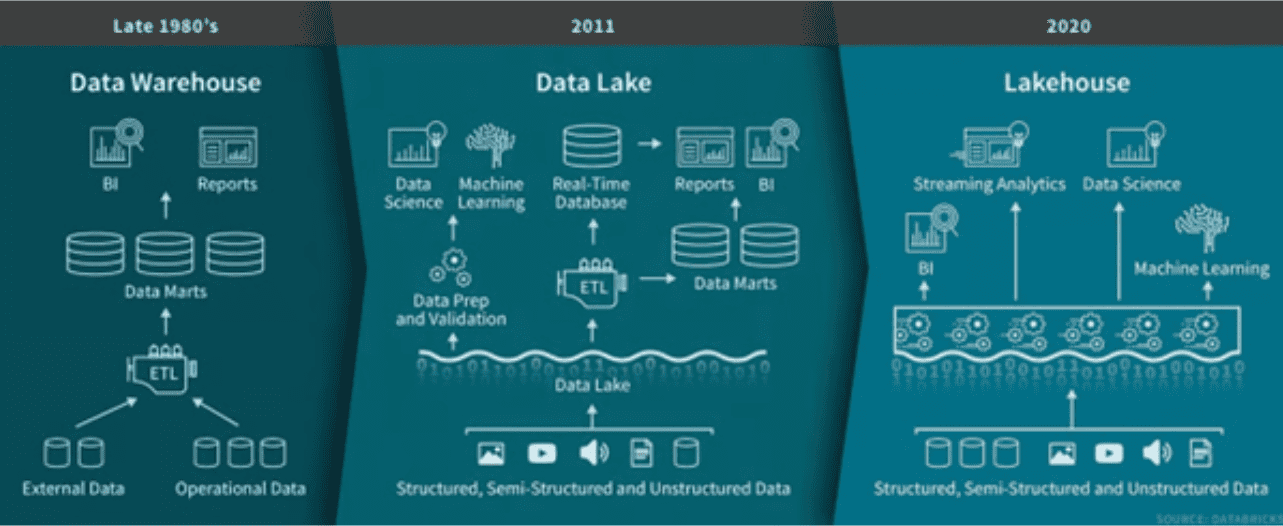
The evolution of data architecture from data warehouses in the late 1980s to data lakes in 2011 and finally to lakehouses in 2020. Image source: Databricks.
A Data Lakehouse combines the scalability and flexibility of a Data Lake with the performance and governance features of a Data Warehouse. This modern data architecture supports a variety of data types — including structured, semi-structured, and unstructured data — in a single system. The Data Lakehouse allows businesses to store, manage, and analyze all their data in one place, making it ideal for AI, machine learning, real-time analytics, and big data applications.
Key Features of Data Lakehouse:
- Support for Diverse Data Types: Handles structured (e.g., relational data), semi-structured (e.g., JSON, XML), and unstructured (e.g., images, videos, IoT data).
- Schema-on-Read & Schema-on-Write: Flexible for raw data ingestion and structured data storage for analytics.
- Optimized for AI/ML: Built for machine learning, AI, and real-time data processing.
- Unified Storage: Combines the low-cost, scalable storage of a data lake with the performance and governance of a data warehouse.
- Cost Efficiency: Reduces operational costs with cloud-native storage and pay-as-you-go models.
Ideal Use Cases for Data Lakehouse:
- Big Data Analytics: Processing vast amounts of structured and unstructured data for insights.
- Machine Learning and AI: Enabling feature engineering, model training, and real-time inference.
- Real-Time Data Processing: Supports fraud detection, recommendation systems, and IoT analytics.
- Enterprise Data Consolidation: Unifying data silos and reducing complexity by storing all data in one platform.
Key Differences Between Data Lakehouse and Traditional EDW
| Feature | Traditional EDW | Data Lakehouse |
| Data Types Supported | Primarily structured data | Structured, semi-structured, and unstructured data |
| Storage Format | Proprietary, optimized for structured data | Open formats (e.g., Parquet, Delta Lake) |
| Schema Management | Schema-on-write (structured before ingestion) | Schema-on-read & schema-on-write (flexible) |
| Processing Engine | SQL-based engines (e.g., Snowflake, Redshift) | Multi-engine support (e.g., Apache Spark, Presto) |
| Cost Efficiency | Expensive due to specialized hardware and ETL processes | More cost-effective with cloud storage and open-source tools |
| Scalability | Limited scalability for massive unstructured data | Easily scalable for large data volumes and diverse data types |
| Real-Time Data Processing | Limited real-time capabilities | Supports real-time ingestion and streaming analytics |
| Machine Learning Support | Limited, often requires exporting data | Built-in integration with machine learning frameworks (e.g., Databricks ML) |
| Data Governance | Strong governance, ideal for regulated industries | Modern governance features, but more complex for diverse data types |
| Use Cases | Business intelligence, financial reporting, regulatory compliance | Big data analytics, AI/ML pipelines, IoT, real-time data processing |
Architecture Comparison: Data Lakehouse vs. Data Warehouse
Data Warehouse Architecture
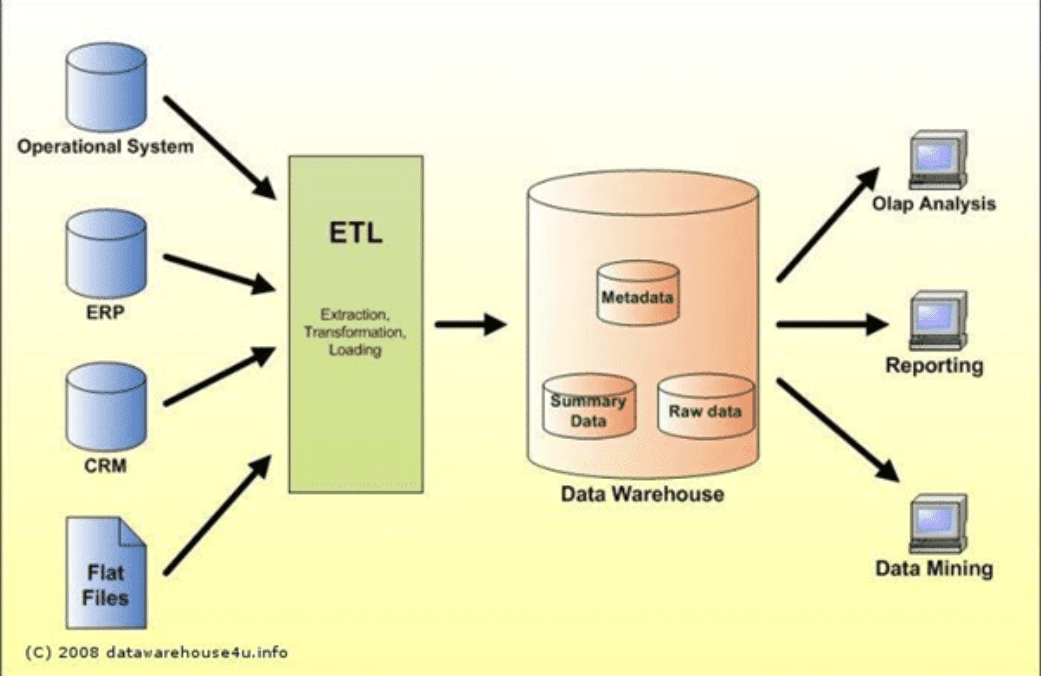
Traditional data warehouses follow a rigid structure designed to optimize query performance. They rely heavily on ETL (Extract, Transform, Load) processes to clean and format data before loading it into the system.
- Storage: Optimized for structured data with columnar formats
- Data Processing: SQL-based engines optimized for fast querying
- Governance: Strong, with excellent data consistency and security measures
- Integration: Primarily integrates with structured data sources.
Data Lakehouse Architecture
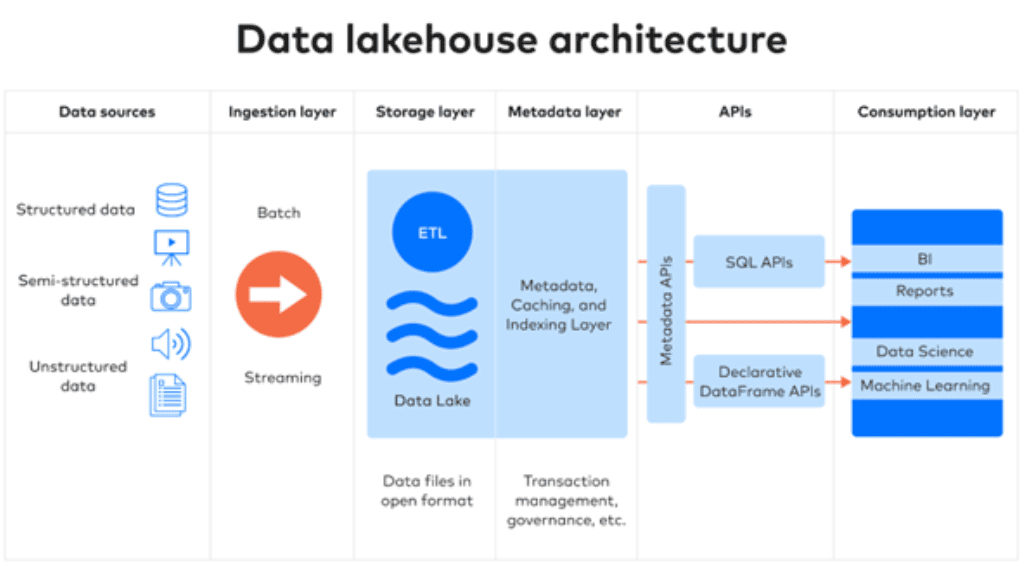
A Data Lakehouse architecture combines several key layers, each playing an essential role in ensuring the flexibility, scalability, and performance of the system:
Ingestion Layer
The ingestion layer gathers data from multiple sources, including batch and real-time streaming data. While traditional data warehouses use ETL (Extract, Transform, Load) to process data, data lakehouses often employ ELT (Extract, Load, Transform). This means raw data is first loaded into storage, and only when needed for analysis does it undergo transformation, offering more flexibility and efficiency.
Storage Layer
The storage layer is typically built on cloud object storage (e.g., AWS S3, Azure Data Lake Storage). This makes it easy to scale as data volumes grow, offering cost-effective storage for massive datasets, both structured and unstructured.
Metadata Layer
The metadata layer provides a unified catalog of metadata for every object in the storage system. It enables key capabilities that data lakes can’t perform, such as indexing for faster queries, enforcing schemas, and applying governance and quality controls.
API Layer
The API layer allows users to connect external tools for advanced analytics. This enables easy integration with BI tools, machine learning frameworks, and data science applications, ensuring flexibility in how data is consumed.
Consumption Layer
The consumption layer hosts client applications and tools for BI, machine learning, and other data science projects. It is where the data is used for analysis, reporting, and decision-making, providing accessible interfaces for both technical and non-technical users.
When to Use Data Lakehouses vs. Traditional Data Warehouses
When to Use a Data Warehouse:
- Your organization focuses on structured data for reporting, business intelligence, and compliance.
- You need high-performance query processing and reliable data governance.
- Your data integration needs are primarily related to structured systems like ERP or CRM.
When to Use a Data Lakehouse:
- Your organization needs to store diverse data types (e.g., unstructured data like images and IoT data) alongside structured data.
- You’re working with big data analytics, AI/ML, or real-time data processing.
- You want a cost-effective, scalable solution that can integrate data from multiple sources and handle both structured and unstructured workloads.
Hybrid Solutions: Combining Data Lakehouses and Data Warehouses
Many businesses are opting for a hybrid solution that leverages both Data Lakehouses and Traditional Data Warehouses. This allows them to store structured data in a warehouse for fast analytics and use the lakehouse for handling big data, machine learning, and real-time analytics.
Benefits of a Hybrid Approach:
- Optimized Storage: Use the data lakehouse for low-cost, flexible storage and the warehouse for fast querying.
- Real-Time and Historical Analytics: Combine real-time insights from a lakehouse with structured historical reporting from a warehouse.
- Comprehensive Data Integration: Store diverse datasets in the lakehouse and use the warehouse for structured, cleaned data.
Conclusion: Which One is Right for You?
In summary, both Data Lakehouses and Traditional Data Warehouses serve distinct purposes. Data Warehouses are ideal for businesses that require optimized query performance and structured data analytics, particularly for business intelligence and regulatory compliance.
On the other hand, Data Lakehouses are perfect for businesses that need to manage massive, diverse datasets and want to integrate AI, machine learning, and real-time analytics into their workflows. They offer scalability, cost efficiency, and flexibility, making them a dominant architecture for modern data-driven enterprises.
At CMC Global, we’re proud to be an official Databricks Consulting & SI partner, helping businesses modernize their data infrastructure and unlock real value from their data. With our expertise in Databricks and the Data Lakehouse architecture, we guide businesses through the transition to more agile, scalable, and cost-effective data solutions, ensuring your strategy is aligned with the latest advancements in AI and machine learning.



